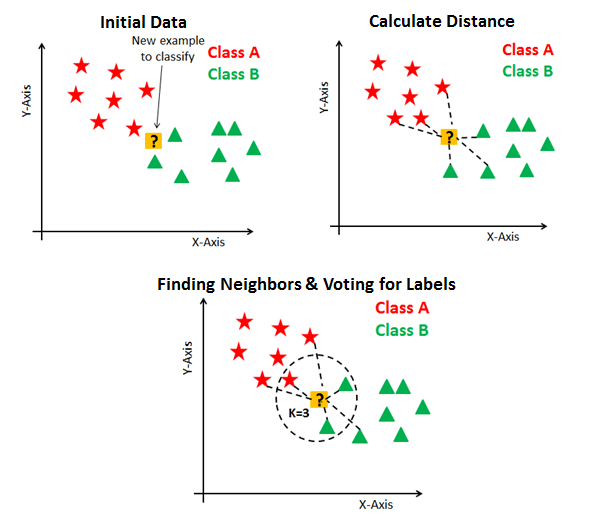
K-Nearest neighbor clustering¶
Nearest Neighbors is a simple algorithm widely used in predictive analysis to cluster data by assigning an item to a cluster by determining what other items are most similar to it.
Not to be confused with k-Means clustering¶
k-Means Clustering is an unsupervised learning algorithm that is used for clustering whereas KNN is a supervised learning algorithm used for classification
Implementation using python’s scikit-learn module¶
from sklearn.neighbors import NearestNeighbors
nbrs = NearestNeighbors()
nbrs.fit(data)
new_obs = np.array([[5. , 3.5, 1.6, 0.3]])
dists, knbrs = nbrs.kneighbors(new_obs)
only_nbrs = nbrs.kneighbors(new_obs,
return_distance=False)
Advantages¶
No training period since KNN is a Lazy Learner (Instance based learning)
New data can be added seamlessly without impacting accuracy of the algorithm
Easy to implement
Disadvantages¶
Does not work well with large datasets
Need feature scaling
Sensitive to noisy data, missing values and outliers